一、MME-CoT 是什么?
MME-CoT(Multimodal Multifaceted Evaluation for Chain-of-Thought)是由香港中文大學(深圳)、香港中文大學、字節跳動、南京大學、上海人工智能實驗室、賓夕法尼亞大學和清華大學等頂尖機構聯合推出的多模態模型鏈式思維推理能力評估框架。
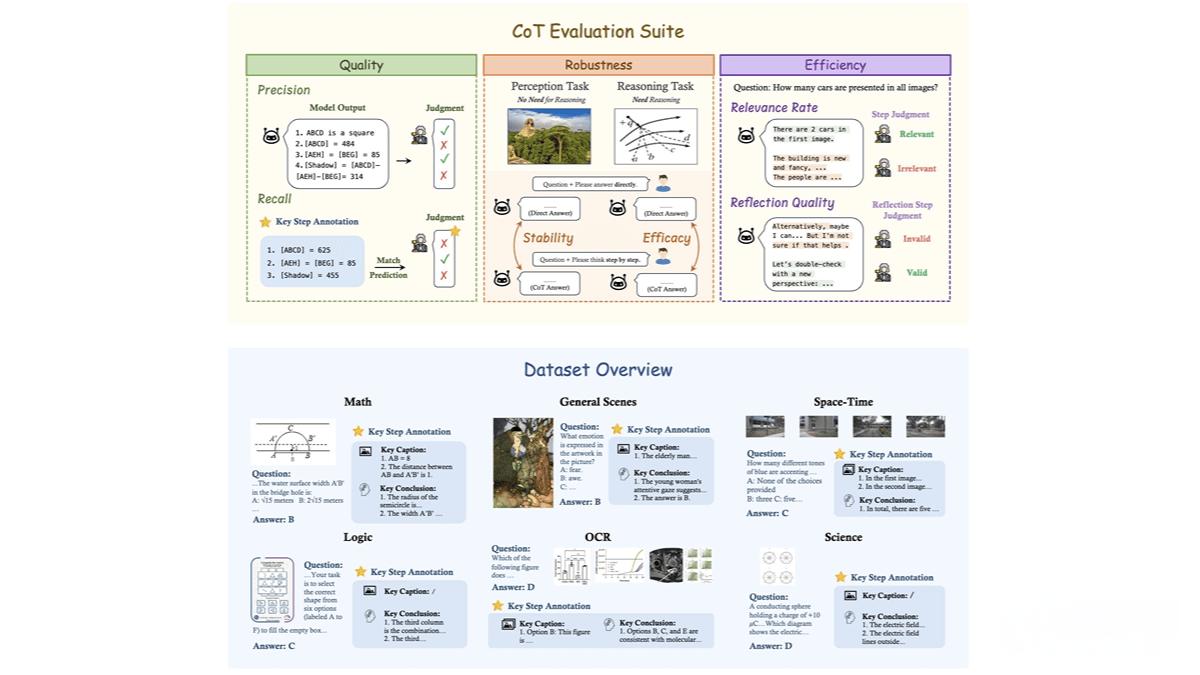
這一框架旨在全面評估大型多模態模型(LMMs)在復雜推理任務中的表現,涵蓋數學、科學、OCR、邏輯、時空和一般場景等六個核心領域。通過 1,130 個精心設計的問題,MME-CoT 為研究人員提供了一個標準化的基準工具,用于測試模型的推理質量、魯棒性和效率。
二、MME-CoT 的核心功能
-
多領域推理能力評估 MME-CoT 覆蓋了六個主要領域,包括數學、科學、OCR、邏輯、時空和一般場景,全面測試模型在不同場景下的推理能力。
-
細粒度推理質量評估 每個問題都標注了關鍵推理步驟和參考圖像描述,通過召回率(Recall)和精確率(Precision)評估推理步驟的邏輯合理性和準確性。
-
模型推理問題揭示 MME-CoT 的實驗結果揭示了當前多模態模型在 CoT 推理中存在的問題,例如反思機制的低效性和對感知任務的干擾。
-
為模型優化提供參考 通過細粒度的評估指標,MME-CoT 為多模態模型的設計和優化提供了重要參考,幫助研究人員改進模型的推理能力。
三、MME-CoT 的技術原理
-
多模態數據集構建 MME-CoT 構建了一個高質量的多模態數據集,包含 1,130 個問題,覆蓋六個領域和 17 個子類別。每個問題都標注了關鍵推理步驟和參考圖像描述,用于評估模型的推理過程。
-
細粒度評估指標
-
推理質量:基于召回率和精確率,評估推理步驟的邏輯合理性和準確性。
-
推理魯棒性:通過穩定性(Stability)和效能(Efficacy),評估 CoT 對感知任務和推理任務的影響。
-
推理效率:基于相關性比例(Relevance Rate)和反思質量(Reflection Quality),評估推理步驟的相關性和反思的有效性。
-
-
推理步驟解析與評估 使用 GPT-4 等模型將模型輸出解析為邏輯推理、圖像描述和背景信息等步驟,逐一對步驟進行評估,確保評估的全面性和準確性。
四、MME-CoT 的應用場景
-
模型評估與比較 MME-CoT 作為標準化基準框架,可用于評估和比較不同多模態模型在推理質量、魯棒性和效率方面的表現。
-
模型優化 基于細粒度評估指標,MME-CoT 揭示模型在推理過程中的問題,為優化模型提供明確的方向。
-
多模態研究 為多模態推理研究提供工具,幫助研究人員探索新的模型架構和訓練方法。
-
教育與培訓 MME-CoT 可用于教育領域,幫助學生和研究人員理解多模態模型的推理邏輯。
-
行業應用 在智能教育、自動駕駛、醫療影像等領域,MME-CoT 可用于評估和改進模型的實際應用表現。
五、MME-CoT 的項目資源
-
GitHub 倉庫:https://github.com/CaraJ7/MME-CoT
-
HuggingFace 模型庫:https://huggingface.co/datasets/CaraJ/MME-CoT
-
arXiv 技術論文:https://arxiv.org/pdf/2502.09621
六、結語
MME-CoT 的推出為多模態模型的研究和優化提供了重要工具,其全面的評估框架和細粒度的指標體系為 AI 領域的發展注入了新的活力。無論是研究人員、開發者還是行業應用者,都可以通過 MME-CoT 框架提升對多模態模型的理解和應用能力,推動 AI 技術的進一步發展。



















