










Llama 3是什么
Llama 3是Meta公司最新開源推出的新一代大型語言模型(LLM),包含8B和70B兩種參數(shù)規(guī)模的模型,標(biāo)志著開源人工智能領(lǐng)域的又一重大進步。作為Llama系列的第三代產(chǎn)品,Llama 3不僅繼承了前代模型的強大功能,還通過一系列創(chuàng)新和改進,提供了更高效、更可靠的AI解決方案,旨在通過先進的自然語言處理技術(shù),支持廣泛的應(yīng)用場景,包括但不限于編程、問題解決、翻譯和對話生成,大家快來奇想AI導(dǎo)航網(wǎng)!
Llama 3的系列型號
Llama 3目前提供了兩種型號,分別為8B(80億參數(shù))和70B(700億參數(shù))的版本,這兩種型號旨在滿足不同層次的應(yīng)用需求,為用戶提供了靈活性和選擇的自由度。
- Llama-3-8B:8B參數(shù)模型,這是一個相對較小但高效的模型,擁有80億個參數(shù)。專為需要快速推理和較少計算資源的應(yīng)用場景設(shè)計,同時保持了較高的性能標(biāo)準(zhǔn)。
- Llama-3-70B:70B參數(shù)模型,這是一個更大規(guī)模的模型,擁有700億個參數(shù)。它能夠處理更復(fù)雜的任務(wù),提供更深入的語言理解和生成能力,適合對性能要求更高的應(yīng)用。
后續(xù),Llama 3 還會推出 400B 參數(shù)規(guī)模的模型,目前還在訓(xùn)練中。Meta 還表示等完成 Llama 3 的訓(xùn)練,還將發(fā)布一份詳細的研究論文。
Llama 3的官網(wǎng)入口
- 官方項目主頁:https://llama.meta.com/llama3/
- GitHub模型權(quán)重和代碼:https://github.com/meta-llama/llama3/
- Hugging Face模型:https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6
Llama 3的改進地方
- 參數(shù)規(guī)模:Llama 3提供了8B和70B兩種參數(shù)規(guī)模的模型,相比Llama 2,參數(shù)數(shù)量的增加使得模型能夠捕捉和學(xué)習(xí)更復(fù)雜的語言模式。
- 訓(xùn)練數(shù)據(jù)集:Llama 3的訓(xùn)練數(shù)據(jù)集比Llama 2大了7倍,包含了超過15萬億個token,其中包括4倍的代碼數(shù)據(jù),這使得Llama 3在理解和生成代碼方面更加出色。
- 模型架構(gòu):Llama 3采用了更高效的分詞器和分組查詢注意力(Grouped Query Attention, GQA)技術(shù),提高了模型的推理效率和處理長文本的能力。
- 性能提升:通過改進的預(yù)訓(xùn)練和后訓(xùn)練過程,Llama 3在減少錯誤拒絕率、提升響應(yīng)對齊和增加模型響應(yīng)多樣性方面取得了進步。
- 安全性:引入了Llama Guard 2等新的信任和安全工具,以及Code Shield和CyberSec Eval 2,增強了模型的安全性和可靠性。
- 多語言支持:Llama 3在預(yù)訓(xùn)練數(shù)據(jù)中加入了超過30種語言的高質(zhì)量非英語數(shù)據(jù),為未來的多語言能力打下了基礎(chǔ)。
- 推理和代碼生成:Llama 3在推理、代碼生成和指令跟隨等方面展現(xiàn)了大幅提升的能力,使其在復(fù)雜任務(wù)處理上更加精準(zhǔn)和高效。
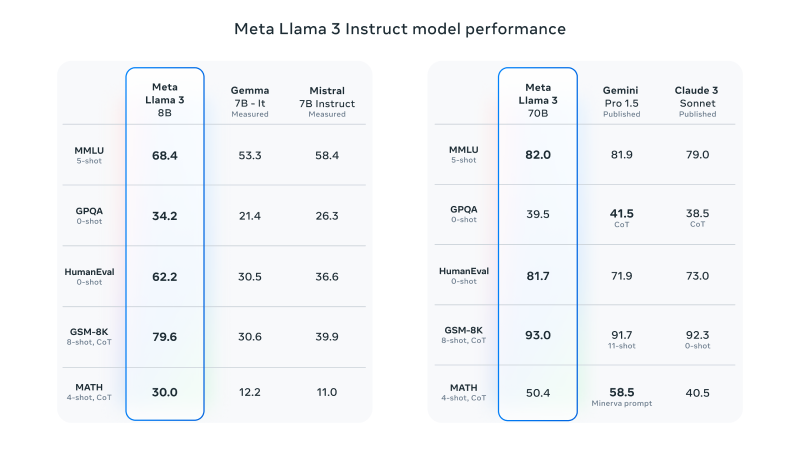
Llama 3的性能評估
根據(jù)Meta的官方博客,經(jīng)指令微調(diào)后的 Llama 3 8B 模型在MMLU、GPQA、HumanEval、GSM-8K、MATH等數(shù)據(jù)集基準(zhǔn)測試中都優(yōu)于同等級參數(shù)規(guī)模的模型(Gemma 7B、Mistral 7B),而微調(diào)后的 Llama 3 70B 在 MLLU、HumanEval、GSM-8K 等基準(zhǔn)測試中也都優(yōu)于同等規(guī)模的 Gemini Pro 1.5 和 Claude 3 Sonnet 模型。
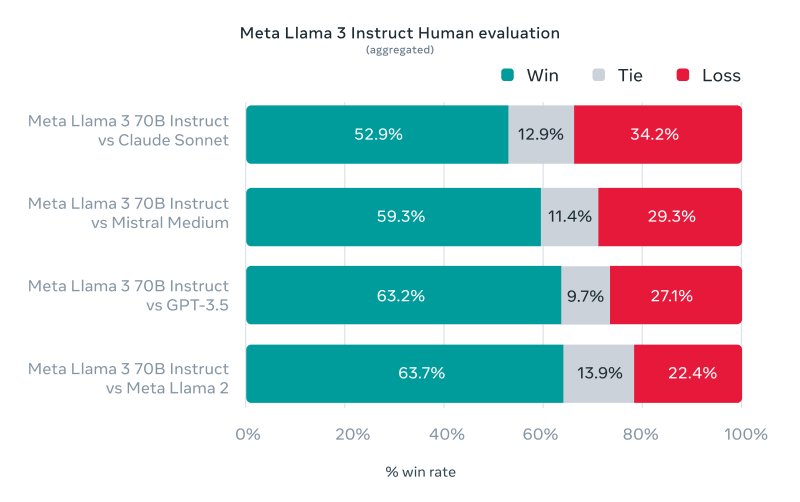
此外,Meta還開發(fā)了一套新的高質(zhì)量人類評估集,包含 1800 個提示,涵蓋 12 個關(guān)鍵用例:尋求建議、頭腦風(fēng)暴、分類、封閉式問答、編碼、創(chuàng)意寫作、提取、塑造角色/角色、開放式問答、推理、重寫和總結(jié)。通過與Claude Sonnet、Mistral Medium和GPT-3.5等競爭模型的比較,人類評估者基于該評估集進行了偏好排名,結(jié)果顯示Llama 3在真實世界場景中的性能非常出色,最低都有52.9%的勝出率。
Llama 3的技術(shù)架構(gòu)
- 解碼器架構(gòu):Llama 3采用了解碼器(decoder-only)架構(gòu),這是一種標(biāo)準(zhǔn)的Transformer模型架構(gòu),主要用于處理自然語言生成任務(wù)。
- 分詞器和詞匯量:Llama 3使用了具有128K個token的分詞器,這使得模型能夠更高效地編碼語言,從而顯著提升性能。
- 分組查詢注意力(Grouped Query Attention, GQA):為了提高推理效率,Llama 3在8B和70B模型中都采用了GQA技術(shù)。這種技術(shù)通過將注意力機制中的查詢分組,減少了計算量,同時保持了模型的性能。
- 長序列處理:Llama 3支持長達8,192個token的序列,使用掩碼(masking)技術(shù)確保自注意力(self-attention)不會跨越文檔邊界,這對于處理長文本尤其重要。
- 預(yù)訓(xùn)練數(shù)據(jù)集:Llama 3在超過15TB的token上進行了預(yù)訓(xùn)練,這個數(shù)據(jù)集不僅規(guī)模巨大,而且質(zhì)量高,為模型提供了豐富的語言信息。
- 多語言數(shù)據(jù):為了支持多語言能力,Llama 3的預(yù)訓(xùn)練數(shù)據(jù)集包含了超過5%的非英語高質(zhì)量數(shù)據(jù),涵蓋了超過30種語言。
- 數(shù)據(jù)過濾和質(zhì)量控制:Llama 3的開發(fā)團隊開發(fā)了一系列數(shù)據(jù)過濾管道,包括啟發(fā)式過濾器、NSFW(不適合工作場所)過濾器、語義去重方法和文本分類器,以確保訓(xùn)練數(shù)據(jù)的高質(zhì)量。
- 擴展性和并行化:Llama 3的訓(xùn)練過程中采用了數(shù)據(jù)并行化、模型并行化和流水線并行化,這些技術(shù)的應(yīng)用使得模型能夠高效地在大量GPU上進行訓(xùn)練。
- 指令微調(diào)(Instruction Fine-Tuning):Llama 3在預(yù)訓(xùn)練模型的基礎(chǔ)上,通過指令微調(diào)進一步提升了模型在特定任務(wù)上的表現(xiàn),如對話和編程任務(wù)。
如何使用Llama 3
開發(fā)人員
Meta已在GitHub、Hugging Face、Replicate上開源其Llama 3模型,開發(fā)人員可使用torchtune等工具對Llama 3進行定制和微調(diào),以適應(yīng)特定的用例和需求,感興趣的開發(fā)者可以查看官方的入門指南并前往下載部署。
- 官方模型下載:https://llama.meta.com/llama-downloads
- GitHub地址:https://github.com/meta-llama/llama3/
- Hugging Face地址:https://huggingface.co/meta-llama
- Replicate地址:https://replicate.com/meta
普通用戶
不懂技術(shù)的普通用戶想要體驗Llama 3可以通過以下方式使用:
- 訪問Meta最新推出的Meta AI聊天助手進行體驗(注:Meta.AI會鎖區(qū),只有部分國家可使用)
- 訪問Replicate提供的Chat with Llama進行體驗https://llama3.replicate.dev/
- 使用Hugging Chat(https://huggingface.co/chat/),可手動將模型切換至Llama 3





