DeepSeek發(fā)布FlashMLA,助力大語言模型高效解碼
FlashMLA是什么?
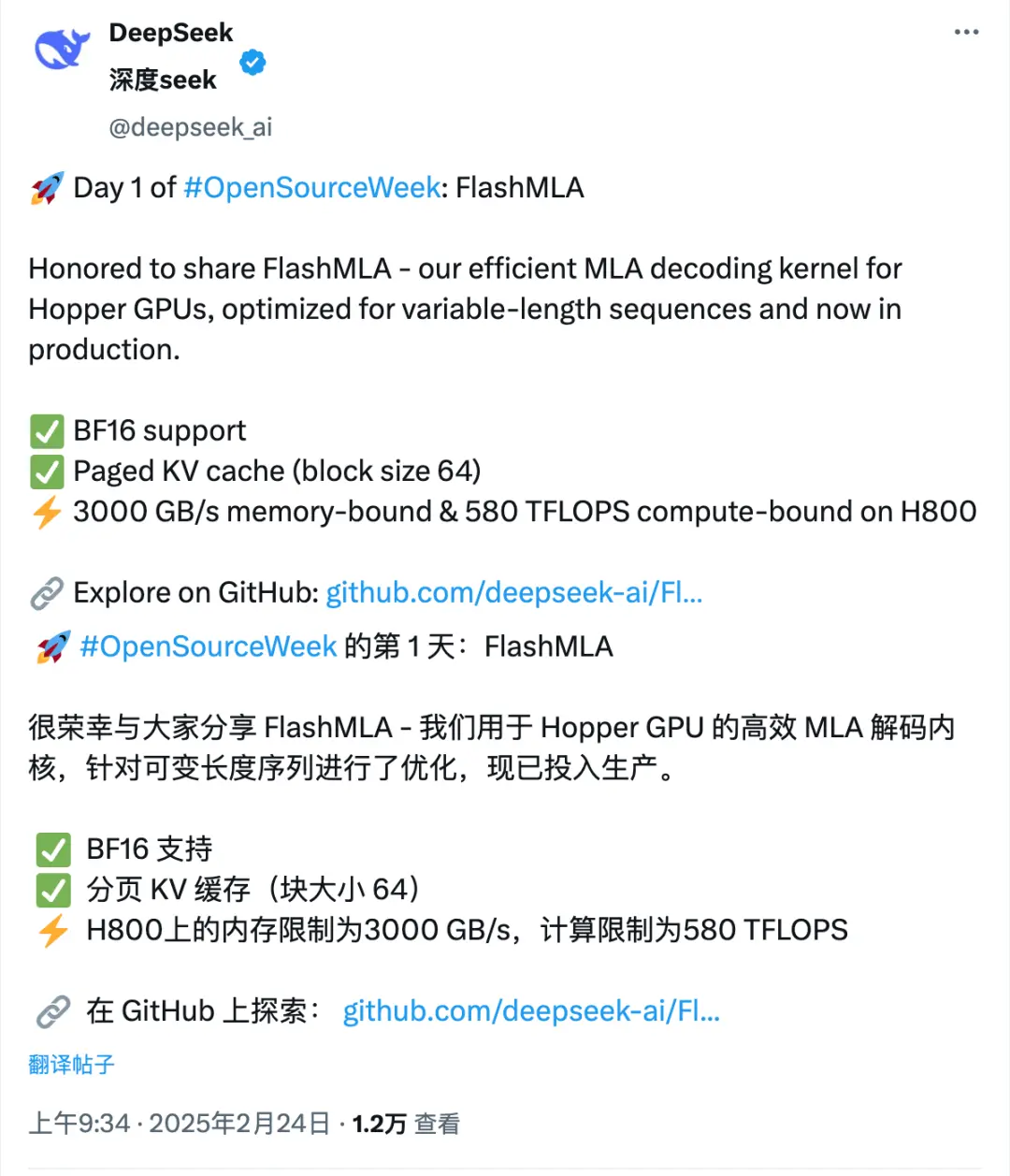
在AI技術(shù)飛速發(fā)展的今天,大語言模型(LLM)的應(yīng)用場景日益廣泛,但解碼效率和性能一直是制約其發(fā)展的關(guān)鍵瓶頸。為了解決這一問題,DeepSeek團(tuán)隊(duì)在2025年2月24日的OpenSourceWeek活動(dòng)中發(fā)布了全新開源項(xiàng)目——FlashMLA。這一項(xiàng)目專為NVIDIA Hopper架構(gòu)GPU(如H800)優(yōu)化,旨在提升大語言模型的解碼效率和性能。
FlashMLA(Flash Multi-Layer Attention)是一個(gè)高效的多層注意力解碼內(nèi)核,針對可變長度序列服務(wù)進(jìn)行了深度優(yōu)化。它能夠顯著提升AI推理任務(wù)的效率,特別適用于需要快速響應(yīng)的場景。FlashMLA的運(yùn)行要求包括NVIDIA Hopper GPU、CUDA 12.3及以上版本以及PyTorch 2.0及以上版本。
為什么選擇FlashMLA?——產(chǎn)品優(yōu)勢全解析
-
BF16支持:計(jì)算與內(nèi)存效率雙提升 FlashMLA支持BFloat16(BF16)數(shù)據(jù)類型,這種數(shù)據(jù)格式在保證計(jì)算精度的同時(shí),顯著降低了內(nèi)存占用,提升了計(jì)算效率。
-
分頁KV緩存:高效處理大規(guī)模序列 通過創(chuàng)新的分頁機(jī)制管理鍵值(KV)緩存,F(xiàn)lashMLA能夠以64塊的大小高效處理大規(guī)模序列,極大提升了模型的處理能力。
-
卓越性能:重新定義解碼速度 在搭載CUDA 12.6的H800 SXM5 GPU上,F(xiàn)lashMLA展現(xiàn)了驚人的性能:
-
內(nèi)存受限場景:最高可達(dá)3000 GB/s的帶寬
-
計(jì)算受限場景:實(shí)現(xiàn)580萬億次浮點(diǎn)運(yùn)算每秒(TFLOPS)
-
這些性能指標(biāo)使其成為高性能AI推理任務(wù)的理想選擇。
FlashMLA的典型應(yīng)用場景
FlashMLA的高效解碼能力使其在多個(gè)領(lǐng)域大放異彩:
-
實(shí)時(shí)AI推理 適用于需要快速響應(yīng)的場景,如智能客服、實(shí)時(shí)翻譯等。
-
智能客服:提升對話生成速度,縮短用戶等待時(shí)間。
-
實(shí)時(shí)翻譯:實(shí)現(xiàn)毫秒級響應(yīng),滿足跨語言溝通需求。
-
-
聊天機(jī)器人 加速對話生成,提升交互流暢度,為用戶提供更自然的對話體驗(yàn)。
-
智能問答:快速生成準(zhǔn)確回答,提升用戶體驗(yàn)。
-
虛擬助手:實(shí)現(xiàn)更高效的多輪對話。
-
-
文本生成 提高文本生成效率,適用于內(nèi)容創(chuàng)作、文案生成等場景。
-
自動(dòng)寫作:加快內(nèi)容生成速度,助力高效創(chuàng)作。
-
智能編輯:提升文本處理效率,優(yōu)化編輯流程。
-
FlashMLA使用指南:快速上手
環(huán)境準(zhǔn)備
-
硬件要求:NVIDIA Hopper架構(gòu)GPU(如H800)
-
軟件要求:
-
CUDA 12.3及以上版本
-
PyTorch 2.0及以上版本
-
安裝步驟
-
克隆代碼倉庫:
https://github.com/deepseek-ai/FlashMLA.git git clone
cd FlashMLA
- 安裝依賴:
python setup.py install
性能驗(yàn)證
安裝完成后,可以通過運(yùn)行官方提供的Benchmark測試腳本驗(yàn)證FlashMLA的性能:
python tests/test_flash_mla.py |
在H800 SXM5 GPU上,F(xiàn)lashMLA的表現(xiàn)令人矚目:
-
內(nèi)存受限場景:3000 GB/s的帶寬
-
計(jì)算受限場景:580 TFLOPS的算力
代碼示例
以下是FlashMLA的基本使用示例:
from flash_mla import get_mla_metadata, flash_mla_with_kvcache # 獲取元數(shù)據(jù) tile_scheduler_metadata, num_splits = get_mla_metadata( cache_seqlens, s_q * h_q // h_kv, h_kv ) # 在多層解碼中使用FlashMLA for i in range(num_layers): ... o_i, lse_i = flash_mla_with_kvcache( q_i, kvcache_i, block_table, cache_seqlens, dv, tile_scheduler_metadata, num_splits, causal=True, ) ... |
此代碼展示了如何在多層解碼過程中調(diào)用FlashMLA,幫助開發(fā)者快速實(shí)現(xiàn)高效解碼。
注意事項(xiàng)
-
硬件兼容性:FlashMLA專為Hopper架構(gòu)GPU設(shè)計(jì),不兼容其他架構(gòu)的GPU。
-
版本要求:確保CUDA和PyTorch版本滿足要求,否則可能導(dǎo)致兼容性問題。
開啟高效解碼新紀(jì)元
FlashMLA的發(fā)布,標(biāo)志著DeepSeek在AI技術(shù)領(lǐng)域的又一次突破。通過BF16支持、分頁KV緩存以及卓越的性能表現(xiàn),F(xiàn)lashMLA為大語言模型的高效解碼提供了全新的解決方案。無論是實(shí)時(shí)AI推理、聊天機(jī)器人,還是文本生成,F(xiàn)lashMLA都能幫助開發(fā)者實(shí)現(xiàn)性能的顯著提升。
如果你正在尋找一款能夠提升AI推理效率的工具,不妨立即體驗(yàn)FlashMLA,感受其在高效解碼和推理加速方面的獨(dú)特魅力!



















