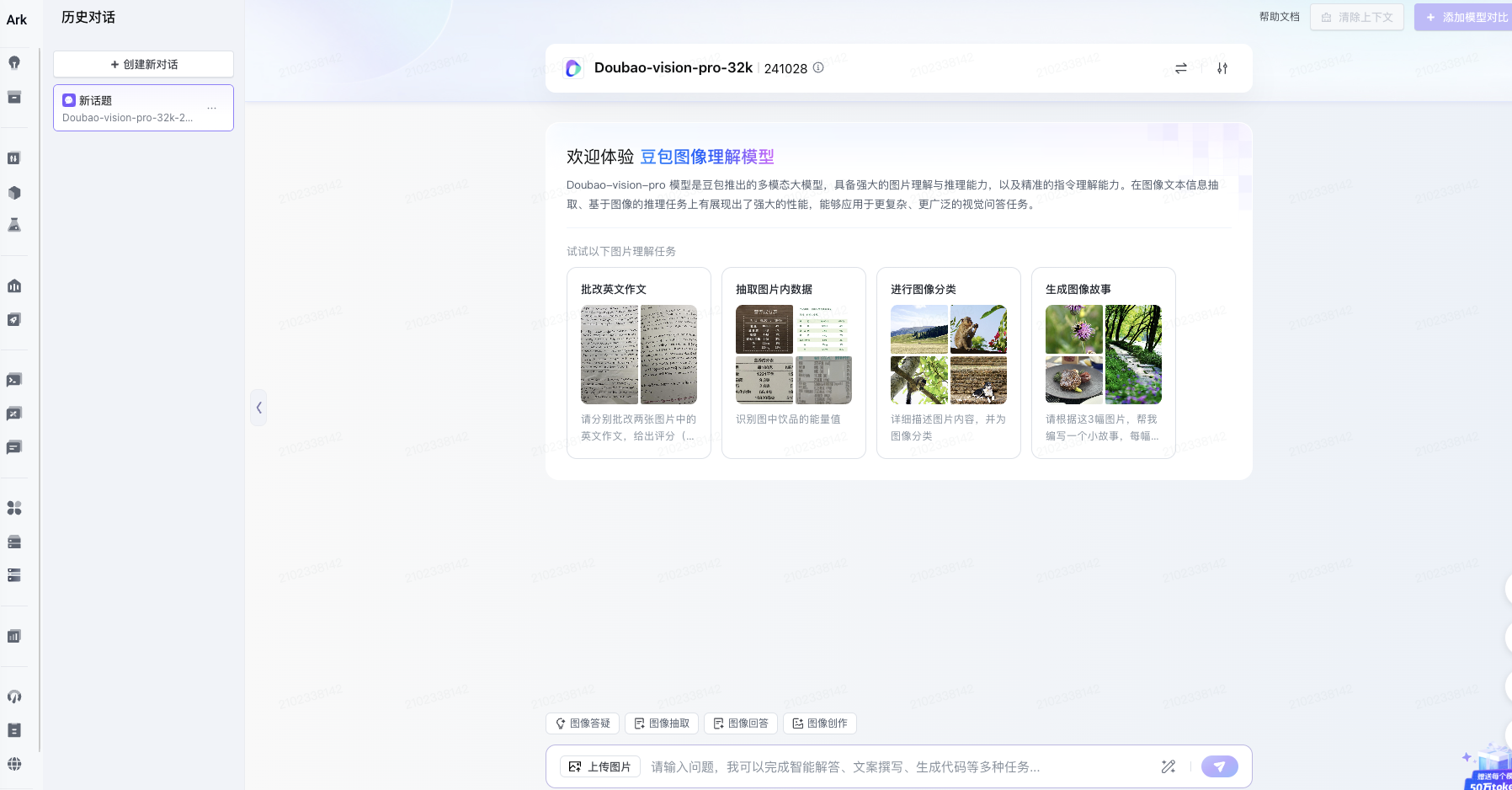
Doubao-vision-pro:豆包視覺(jué)理解模型
Doubao-vision-pro 模型是豆包推出的多模態(tài)大模型,具備強(qiáng)大的圖片理解與推理能力,以及精準(zhǔn)的指令理解能力。模型在圖像文本信息抽取、基于圖像的推理任務(wù)上有展現(xiàn)出了強(qiáng)大的性能,能夠應(yīng)用于更復(fù)雜、更廣泛的視覺(jué)問(wèn)答任務(wù)。
隨著大數(shù)據(jù)時(shí)代的到來(lái),圖像數(shù)據(jù)的數(shù)量激增,使得人們?cè)谝曈X(jué)信息的獲取和分析上遇到了越來(lái)越多的挑戰(zhàn)。傳統(tǒng)的圖像處理方法往往依賴(lài)于手動(dòng)特征提取,這種方法不僅耗時(shí)且難以適應(yīng)不斷變化的圖像數(shù)據(jù)。豆包視覺(jué)理解模型的問(wèn)世旨在利用深度學(xué)習(xí)技術(shù),自動(dòng)化地提取圖像特征并進(jìn)行分析,顯著提升圖像處理的效率和準(zhǔn)確性。
如今,眾多企業(yè)和研究機(jī)構(gòu)對(duì)于視覺(jué)理解的需求不斷增長(zhǎng),尤其在自動(dòng)駕駛、醫(yī)療影像處理、安防監(jiān)控、智能家居等領(lǐng)域,豆包視覺(jué)理解模型以其強(qiáng)大的技術(shù)支撐,成為了這些應(yīng)用場(chǎng)景中的佼佼者。
二、豆包視覺(jué)理解模型的工作原理
豆包視覺(jué)理解模型基于深度學(xué)習(xí)技術(shù),尤其是卷積神經(jīng)網(wǎng)絡(luò)(CNN)。CNN是一種具有強(qiáng)大特征提取能力的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),適合處理圖像數(shù)據(jù)。豆包模型通過(guò)多個(gè)卷積層和池化層的堆疊,能夠有效地捕捉圖像中的空間特征。
1. 數(shù)據(jù)預(yù)處理:在模型訓(xùn)練之前,輸入的數(shù)據(jù)需要進(jìn)行預(yù)處理,包括圖像的縮放、歸一化和數(shù)據(jù)增強(qiáng)等。這一過(guò)程能夠提高模型的魯棒性,減少過(guò)擬合現(xiàn)象。
2. 卷積層:卷積層是模型的核心組成部分,通過(guò)卷積操作提取圖像特征。在這個(gè)過(guò)程中,模型會(huì)學(xué)習(xí)到不同層次的特征,從簡(jiǎn)單的邊緣檢測(cè)到復(fù)雜的形狀識(shí)別。
3. 激活函數(shù):在卷積層之后,模型使用激活函數(shù)(如ReLU)引入非線性特征,使得模型能夠更好地?cái)M合復(fù)雜的數(shù)據(jù)分布。
4. 池化層:池化層的作用是降低特征圖的維度,從而減輕計(jì)算負(fù)擔(dān),提升模型的效率。同時(shí),池化操作還能增強(qiáng)特征對(duì)位置的魯棒性,增加模型的泛化能力。
5. 全連接層:在經(jīng)過(guò)多層卷積和池化后,特征圖會(huì)被展平并輸入全連接層。全連接層負(fù)責(zé)將提取的高層特征融合,進(jìn)行分類(lèi)或回歸任務(wù)。
6. 損失函數(shù)與優(yōu)化器:在訓(xùn)練模型的過(guò)程中,使用損失函數(shù)來(lái)評(píng)估模型輸出與真實(shí)標(biāo)簽之間的差異,并通過(guò)優(yōu)化算法(如Adam或SGD)迭代更新模型參數(shù),以最小化損失。
三、豆包視覺(jué)理解模型的應(yīng)用場(chǎng)景
豆包視覺(jué)理解模型的高效性和準(zhǔn)確性使其在多個(gè)領(lǐng)域中得到了廣泛應(yīng)用,以下是一些典型的應(yīng)用場(chǎng)景:
1. 自動(dòng)駕駛:在自動(dòng)駕駛技術(shù)中,車(chē)輛需要實(shí)時(shí)識(shí)別周?chē)h(huán)境中的行人、交通標(biāo)志、其他車(chē)輛等信息,以確保安全行駛。豆包視覺(jué)理解模型能夠快速而準(zhǔn)確地分析實(shí)時(shí)視頻流,提高自動(dòng)駕駛系統(tǒng)的安全性和可靠性。
2. 醫(yī)療影像處理:醫(yī)療行業(yè)對(duì)于圖像分析的需求十分迫切,尤其是在醫(yī)學(xué)影像(如CT、MRI)中,專(zhuān)家需要快速準(zhǔn)確地識(shí)別病變。豆包視覺(jué)理解模型通過(guò)訓(xùn)練海量的醫(yī)學(xué)影像數(shù)據(jù),幫助醫(yī)生提高診斷的效率,同時(shí)也能輔助進(jìn)行病灶的定位與分割。
3. 安防監(jiān)控:在安防領(lǐng)域,監(jiān)控視頻中經(jīng)常需要對(duì)人群、動(dòng)作等進(jìn)行實(shí)時(shí)分析。豆包視覺(jué)理解模型的引入,可以有效提升安防系統(tǒng)的智能化水平,對(duì)可疑行為進(jìn)行快速識(shí)別,增強(qiáng)公共安全。
4. 智能家居:隨著智能家居的普及,家庭設(shè)備需要具備對(duì)圖像的理解能力,例如,智能攝像頭能夠識(shí)別家庭成員并進(jìn)行安全管理。豆包視覺(jué)理解模型能夠?yàn)橹悄芗揖赢a(chǎn)品提供更為精準(zhǔn)的視覺(jué)識(shí)別能力,提高用戶(hù)體驗(yàn)。
5. 社交媒體:在社交媒體的內(nèi)容管理中,豆包視覺(jué)理解模型可以幫助平臺(tái)進(jìn)行圖像的分類(lèi)和審核,自動(dòng)識(shí)別不當(dāng)內(nèi)容或違規(guī)行為,維護(hù)社區(qū)的健康和安全。
四、豆包視覺(jué)理解模型的未來(lái)發(fā)展趨勢(shì)
盡管豆包視覺(jué)理解模型在多個(gè)領(lǐng)域都顯示出了優(yōu)越的性能,但其未來(lái)的發(fā)展還有許多值得探索的方向:
1. 自監(jiān)督學(xué)習(xí):自監(jiān)督學(xué)習(xí)是一種新興的學(xué)習(xí)方式,利用未標(biāo)記的數(shù)據(jù)進(jìn)行模型預(yù)訓(xùn)練,然后再進(jìn)行微調(diào)。此種方法能夠大大減少對(duì)標(biāo)簽數(shù)據(jù)的依賴(lài),適應(yīng)數(shù)據(jù)的快速變化。
2. 模型壓縮與加速:隨著計(jì)算資源的限制,如何在保證模型性能的前提下進(jìn)行模型壓縮和加速,成為了一個(gè)重要的研究方向。量化、剪枝等技術(shù)能夠有效減少模型的體積和計(jì)算量,適用于移動(dòng)設(shè)備和邊緣計(jì)算。
3. 多模態(tài)學(xué)習(xí):結(jié)合圖像、文本和音頻等多種信息進(jìn)行的多模態(tài)學(xué)習(xí),能夠進(jìn)一步提升模型的理解能力。豆包視覺(jué)理解模型可在此方向上進(jìn)行融合研究,為用戶(hù)提供更為豐富的服務(wù)。
4. 深度強(qiáng)化學(xué)習(xí):通過(guò)引入深度強(qiáng)化學(xué)習(xí),模型能夠在動(dòng)態(tài)環(huán)境中進(jìn)行自主學(xué)習(xí)與決策,不斷提升適應(yīng)性。這對(duì)于自動(dòng)駕駛和智能機(jī)器人等領(lǐng)域而言,都是一種潛在的技術(shù)突破。
五、總結(jié)
豆包視覺(jué)理解模型代表了人工智能圖像處理技術(shù)的前沿,無(wú)論是在理論研究還是在實(shí)際應(yīng)用中,都展現(xiàn)出了巨大的潛力。通過(guò)不斷的創(chuàng)新與發(fā)展,豆包視覺(jué)理解模型將會(huì)為各行各業(yè)帶來(lái)更多的智能化解決方案,推動(dòng)社會(huì)和科技的進(jìn)步。
未來(lái),我們期待豆包視覺(jué)理解模型能夠繼續(xù)突破自身的局限,服務(wù)于更加廣泛的應(yīng)用領(lǐng)域,為人類(lèi)生活帶來(lái)更多的便利和價(jià)值。
隨著大數(shù)據(jù)時(shí)代的到來(lái),圖像數(shù)據(jù)的數(shù)量激增,使得人們?cè)谝曈X(jué)信息的獲取和分析上遇到了越來(lái)越多的挑戰(zhàn)。傳統(tǒng)的圖像處理方法往往依賴(lài)于手動(dòng)特征提取,這種方法不僅耗時(shí)且難以適應(yīng)不斷變化的圖像數(shù)據(jù)。豆包視覺(jué)理解模型的問(wèn)世旨在利用深度學(xué)習(xí)技術(shù),自動(dòng)化地提取圖像特征并進(jìn)行分析,顯著提升圖像處理的效率和準(zhǔn)確性。
如今,眾多企業(yè)和研究機(jī)構(gòu)對(duì)于視覺(jué)理解的需求不斷增長(zhǎng),尤其在自動(dòng)駕駛、醫(yī)療影像處理、安防監(jiān)控、智能家居等領(lǐng)域,豆包視覺(jué)理解模型以其強(qiáng)大的技術(shù)支撐,成為了這些應(yīng)用場(chǎng)景中的佼佼者。
二、豆包視覺(jué)理解模型的工作原理
豆包視覺(jué)理解模型基于深度學(xué)習(xí)技術(shù),尤其是卷積神經(jīng)網(wǎng)絡(luò)(CNN)。CNN是一種具有強(qiáng)大特征提取能力的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),適合處理圖像數(shù)據(jù)。豆包模型通過(guò)多個(gè)卷積層和池化層的堆疊,能夠有效地捕捉圖像中的空間特征。
1. 數(shù)據(jù)預(yù)處理:在模型訓(xùn)練之前,輸入的數(shù)據(jù)需要進(jìn)行預(yù)處理,包括圖像的縮放、歸一化和數(shù)據(jù)增強(qiáng)等。這一過(guò)程能夠提高模型的魯棒性,減少過(guò)擬合現(xiàn)象。
2. 卷積層:卷積層是模型的核心組成部分,通過(guò)卷積操作提取圖像特征。在這個(gè)過(guò)程中,模型會(huì)學(xué)習(xí)到不同層次的特征,從簡(jiǎn)單的邊緣檢測(cè)到復(fù)雜的形狀識(shí)別。
3. 激活函數(shù):在卷積層之后,模型使用激活函數(shù)(如ReLU)引入非線性特征,使得模型能夠更好地?cái)M合復(fù)雜的數(shù)據(jù)分布。
4. 池化層:池化層的作用是降低特征圖的維度,從而減輕計(jì)算負(fù)擔(dān),提升模型的效率。同時(shí),池化操作還能增強(qiáng)特征對(duì)位置的魯棒性,增加模型的泛化能力。
5. 全連接層:在經(jīng)過(guò)多層卷積和池化后,特征圖會(huì)被展平并輸入全連接層。全連接層負(fù)責(zé)將提取的高層特征融合,進(jìn)行分類(lèi)或回歸任務(wù)。
6. 損失函數(shù)與優(yōu)化器:在訓(xùn)練模型的過(guò)程中,使用損失函數(shù)來(lái)評(píng)估模型輸出與真實(shí)標(biāo)簽之間的差異,并通過(guò)優(yōu)化算法(如Adam或SGD)迭代更新模型參數(shù),以最小化損失。
三、豆包視覺(jué)理解模型的應(yīng)用場(chǎng)景
豆包視覺(jué)理解模型的高效性和準(zhǔn)確性使其在多個(gè)領(lǐng)域中得到了廣泛應(yīng)用,以下是一些典型的應(yīng)用場(chǎng)景:
1. 自動(dòng)駕駛:在自動(dòng)駕駛技術(shù)中,車(chē)輛需要實(shí)時(shí)識(shí)別周?chē)h(huán)境中的行人、交通標(biāo)志、其他車(chē)輛等信息,以確保安全行駛。豆包視覺(jué)理解模型能夠快速而準(zhǔn)確地分析實(shí)時(shí)視頻流,提高自動(dòng)駕駛系統(tǒng)的安全性和可靠性。
2. 醫(yī)療影像處理:醫(yī)療行業(yè)對(duì)于圖像分析的需求十分迫切,尤其是在醫(yī)學(xué)影像(如CT、MRI)中,專(zhuān)家需要快速準(zhǔn)確地識(shí)別病變。豆包視覺(jué)理解模型通過(guò)訓(xùn)練海量的醫(yī)學(xué)影像數(shù)據(jù),幫助醫(yī)生提高診斷的效率,同時(shí)也能輔助進(jìn)行病灶的定位與分割。
3. 安防監(jiān)控:在安防領(lǐng)域,監(jiān)控視頻中經(jīng)常需要對(duì)人群、動(dòng)作等進(jìn)行實(shí)時(shí)分析。豆包視覺(jué)理解模型的引入,可以有效提升安防系統(tǒng)的智能化水平,對(duì)可疑行為進(jìn)行快速識(shí)別,增強(qiáng)公共安全。
4. 智能家居:隨著智能家居的普及,家庭設(shè)備需要具備對(duì)圖像的理解能力,例如,智能攝像頭能夠識(shí)別家庭成員并進(jìn)行安全管理。豆包視覺(jué)理解模型能夠?yàn)橹悄芗揖赢a(chǎn)品提供更為精準(zhǔn)的視覺(jué)識(shí)別能力,提高用戶(hù)體驗(yàn)。
5. 社交媒體:在社交媒體的內(nèi)容管理中,豆包視覺(jué)理解模型可以幫助平臺(tái)進(jìn)行圖像的分類(lèi)和審核,自動(dòng)識(shí)別不當(dāng)內(nèi)容或違規(guī)行為,維護(hù)社區(qū)的健康和安全。
四、豆包視覺(jué)理解模型的未來(lái)發(fā)展趨勢(shì)
盡管豆包視覺(jué)理解模型在多個(gè)領(lǐng)域都顯示出了優(yōu)越的性能,但其未來(lái)的發(fā)展還有許多值得探索的方向:
1. 自監(jiān)督學(xué)習(xí):自監(jiān)督學(xué)習(xí)是一種新興的學(xué)習(xí)方式,利用未標(biāo)記的數(shù)據(jù)進(jìn)行模型預(yù)訓(xùn)練,然后再進(jìn)行微調(diào)。此種方法能夠大大減少對(duì)標(biāo)簽數(shù)據(jù)的依賴(lài),適應(yīng)數(shù)據(jù)的快速變化。
2. 模型壓縮與加速:隨著計(jì)算資源的限制,如何在保證模型性能的前提下進(jìn)行模型壓縮和加速,成為了一個(gè)重要的研究方向。量化、剪枝等技術(shù)能夠有效減少模型的體積和計(jì)算量,適用于移動(dòng)設(shè)備和邊緣計(jì)算。
3. 多模態(tài)學(xué)習(xí):結(jié)合圖像、文本和音頻等多種信息進(jìn)行的多模態(tài)學(xué)習(xí),能夠進(jìn)一步提升模型的理解能力。豆包視覺(jué)理解模型可在此方向上進(jìn)行融合研究,為用戶(hù)提供更為豐富的服務(wù)。
4. 深度強(qiáng)化學(xué)習(xí):通過(guò)引入深度強(qiáng)化學(xué)習(xí),模型能夠在動(dòng)態(tài)環(huán)境中進(jìn)行自主學(xué)習(xí)與決策,不斷提升適應(yīng)性。這對(duì)于自動(dòng)駕駛和智能機(jī)器人等領(lǐng)域而言,都是一種潛在的技術(shù)突破。
五、總結(jié)
豆包視覺(jué)理解模型代表了人工智能圖像處理技術(shù)的前沿,無(wú)論是在理論研究還是在實(shí)際應(yīng)用中,都展現(xiàn)出了巨大的潛力。通過(guò)不斷的創(chuàng)新與發(fā)展,豆包視覺(jué)理解模型將會(huì)為各行各業(yè)帶來(lái)更多的智能化解決方案,推動(dòng)社會(huì)和科技的進(jìn)步。
未來(lái),我們期待豆包視覺(jué)理解模型能夠繼續(xù)突破自身的局限,服務(wù)于更加廣泛的應(yīng)用領(lǐng)域,為人類(lèi)生活帶來(lái)更多的便利和價(jià)值。
? 版權(quán)聲明
本站文章版權(quán)歸奇想AI導(dǎo)航網(wǎng)所有,未經(jīng)允許禁止任何形式的轉(zhuǎn)載。
相關(guān)文章




















奇想AI導(dǎo)航網(wǎng)收錄了國(guó)內(nèi)外數(shù)百個(gè)不同類(lèi)型的AI工具,每日更新和添加最新AI工具,奇想AI導(dǎo)航網(wǎng)還推薦了AI學(xué)習(xí)開(kāi)發(fā)的常用網(wǎng)站、框架和模型,幫助你加入人工智能浪潮,自動(dòng)化高效完成任務(wù)!
Ctrl + D 或 ? + D 收藏本站到瀏覽器書(shū)簽欄。