在人工智能快速發展的今天,語音技術正在改變我們的生活方式。無論是智能客服、智能家居,還是教育工具,語音理解模型都發揮著重要作用。今天,我們將深入解析由西北工業大學推出的開源語音理解模型——OSUM,探索它如何助力語音識別、情感分析等多任務場景。
一、OSUM是什么?
-
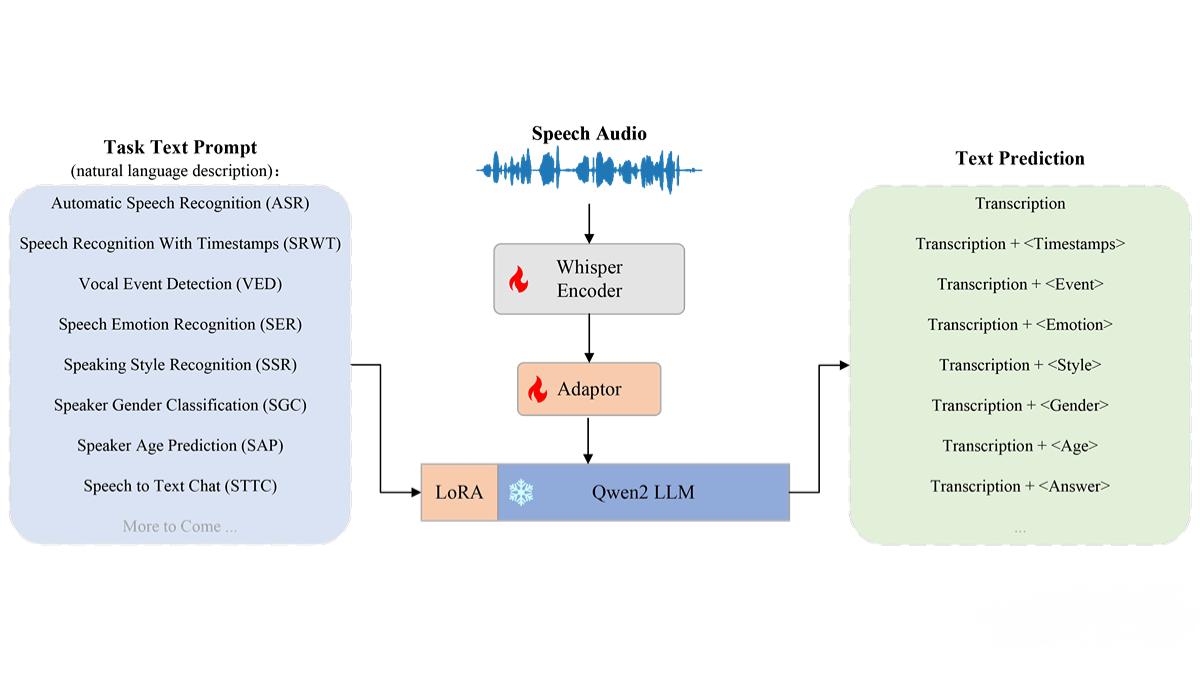
OSUM(Open Speech Understanding Model)是由西北工業大學計算機學院音頻、語音與語言處理研究組開發的開源語音理解模型。
-
結合Whisper編碼器和Qwen2 LLM,支持語音識別(ASR)、語音情感識別(SER)、說話者性別分類(SGC)等多種任務。
-
基于“ASR+X”多任務訓練策略,實現高效穩定的訓練。
二、OSUM的主要功能
-
語音識別:支持多種語言和方言,準確將語音轉換為文本。
-
帶時間戳的語音識別:輸出每個單詞或短語的起止時間,便于后續處理。
-
語音事件檢測:識別笑聲、咳嗽、背景噪音等特定事件。
-
語音情感識別:分析高興、悲傷、憤怒等情感狀態。
-
說話風格識別:區分新聞播報、客服對話、日常口語等風格。
-
說話者性別和年齡分類:判斷性別和年齡范圍。
-
語音轉文本聊天:將語音輸入轉化為自然語言回復,適用于對話系統。
三、OSUM的技術原理
-
Speech Encoder:采用Whisper-Medium模型(769M參數),負責將語音信號編碼為特征向量。
-
Adaptor:包含3層卷積和4層Transformer,用于適配語音特征與語言模型的輸入。
-
LLM(語言模型):基于Qwen2-7B-Instruct,通過LoRA微調適應多任務需求。
-
多任務訓練策略:
-
ASR+X訓練范式:同時訓練語音識別和附加任務,提升泛化能力。
-
自然語言Prompt:通過不同提示引導模型執行任務。
-
數據處理與訓練:約5萬小時的多樣化語音數據,分為兩階段訓練。
-
四、OSUM的應用場景
-
智能客服:結合語音識別和情感分析,提供個性化服務。
-
智能家居:識別語音指令和背景事件,優化交互體驗。
-
教育工具:分析學生語音,提供學習反饋。
-
心理健康監測:檢測語音情緒變化,輔助評估。
-
多媒體內容創作:自動生成字幕和標簽,輔助視頻編輯。
五、如何獲取和使用OSUM?
-
GitHub倉庫:https://github.com/ASLP-lab/OSUM



















