什么是GAS框架?
GAS(Generative Avatar Synthesis from a Single Image)是一項由卡內基梅隆大學、上海人工智能實驗室和斯坦福大學的研究人員共同開發的前沿技術。該框架能夠從單張圖像生成高質量、視角一致且時間連貫的虛擬形象。通過結合回歸型3D人體重建模型和擴散模型的優勢,GAS在虛擬形象生成領域取得了顯著突破。
GAS的核心在于其獨特的“模式切換器”模塊,能夠區分視角合成和姿態合成任務,從而提升生成效果的準確性和真實性。這一技術不僅為虛擬形象的生成提供了新的可能性,還為多個行業帶來了革命性的變化。
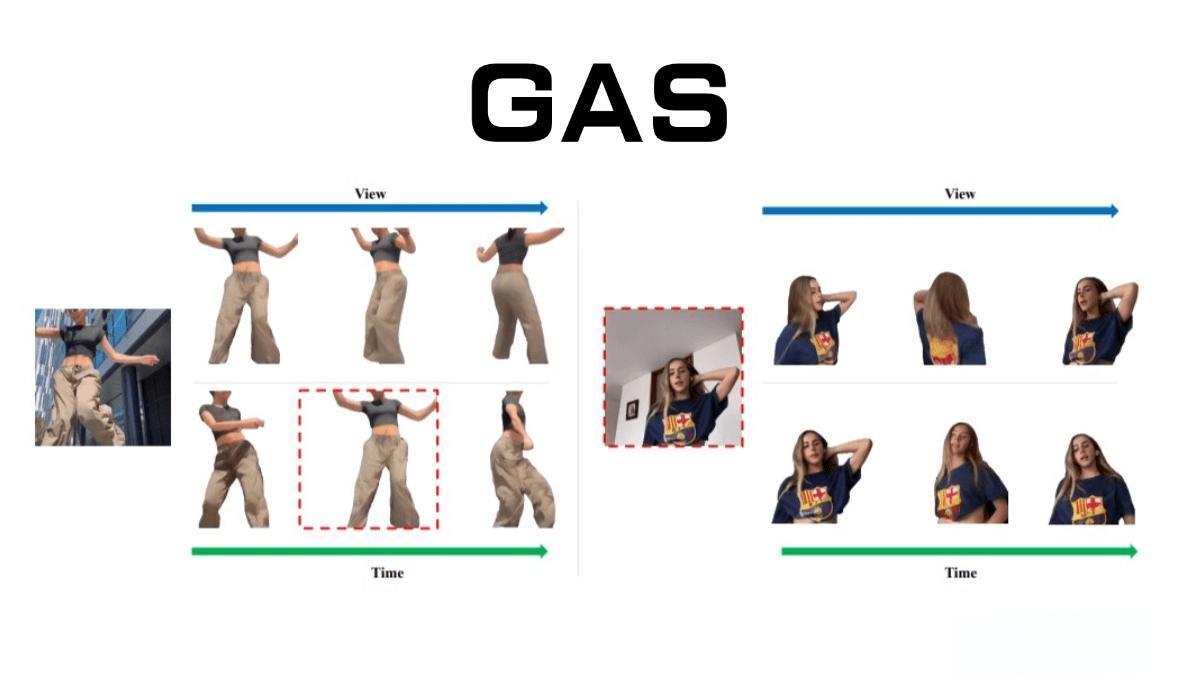
GAS的核心功能
-
視角一致的多視角合成 GAS可以從單張圖像生成高質量的多視角渲染,確保不同視角下的外觀和結構一致性。這對于需要多角度展示的應用場景(如虛擬試衣、游戲建模)尤為重要。
-
時間連貫的動態姿態動畫 通過給定的姿態序列,GAS能夠生成流暢且真實的非剛性形變動畫。這一功能在影視特效、虛擬現實(VR)和體育訓練等領域具有廣闊的應用前景。
-
統一框架與泛化能力 GAS將視角合成和姿態合成任務統一在一個框架內,通過共享模型參數和利用大規模真實數據(如網絡視頻)進行訓練,顯著提升了模型的泛化能力。
-
密集外觀提示 基于3D重建模型生成的密集信息作為條件輸入,GAS確保了生成結果在外觀和結構上的高保真度。
GAS的技術原理
-
3D人體重建與密集條件信號 GAS首先基于回歸型3D人體重建模型(如單視角通用人類NeRF)從輸入圖像生成中間視角或姿態。通過將輸入圖像映射到規范空間并重新定位,生成密集的外觀提示。這些信息為后續的擴散模型提供了豐富的細節和結構信息。
-
視頻擴散模型與統一框架 生成的中間視角或姿態被用作視頻擴散模型的條件輸入,通過擴散模型生成高質量的視角一致性和時間連貫性動畫。GAS的統一框架實現了從姿態合成到視角合成的自然泛化。
-
模式切換器 為了區分視角合成和姿態合成任務,GAS引入了模式切換器模塊。該模塊支持網絡在生成視角時專注于一致性,在生成姿態時專注于真實感變形。
-
真實世界數據的泛化能力 GAS通過結合大規模真實世界視頻(如網絡視頻)進行訓練,顯著提升了對真實場景的適應能力。多樣化的數據來源使得模型能夠適應各種光照、服裝和動作條件。
-
訓練與推理 GAS的訓練分為兩個階段:首先訓練3D人體重建模型,然后凍結該模型并訓練視頻擴散模型。推理時,根據任務性質(視角合成或姿態合成)采用不同的分類器自由引導(CFG)策略。
GAS的應用場景
-
游戲和虛擬現實(VR) GAS可以從單張圖像生成高質量的虛擬形象,支持多視角和動態姿態的連貫合成,為游戲開發和VR體驗提供全新的可能性。
-
影視制作 在影視特效和動畫制作中,GAS能夠快速生成逼真的虛擬角色,顯著減少傳統建模和動畫制作的時間和成本。
-
體育和健身 通過從單張圖像生成動態虛擬形象,GAS可用于創建個性化的運動動畫,幫助運動員分析動作或用于健身應用中。
-
時尚和服裝設計 GAS能夠生成不同姿態和視角的虛擬形象,幫助設計師快速預覽服裝效果,提升設計效率。
GAS的項目資源
-
項目官網:GAS官方頁面
-
技術論文:GAS的arXiv論文
結語
GAS框架代表了AI技術在虛擬形象生成領域的最新進展,其強大的視角一致性和時間連貫性生成能力為多個行業帶來了全新的可能性。無論是游戲開發、影視制作,還是體育訓練和服裝設計,GAS都展現出了巨大的應用價值。隨著技術的不斷進步,GAS有望在未來推動更多創新應用的實現。



















