HumanOmni:專注人類中心場景的多模態(tài)大模型,助力影視、教育與營銷領域創(chuàng)新
在人工智能領域,多模態(tài)大模型正逐漸成為研究和應用的熱點。HumanOmni作為一款專注于人類中心場景的多模態(tài)大模型,通過融合視覺、聽覺和文本信息,為影視、教育、營銷和內(nèi)容創(chuàng)作等領域帶來了全新的可能性。本文將深入解析HumanOmni的技術優(yōu)勢、應用場景及其在不同領域的應用潛力。
HumanOmni的技術優(yōu)勢
HumanOmni的核心優(yōu)勢在于其多模態(tài)融合架構和動態(tài)權重調整機制。通過三個專門的分支(面部相關、身體相關和交互相關),模型能夠全面理解人類行為、情感和交互。動態(tài)權重調整機制使得模型能夠根據(jù)不同任務需求,靈活調整各分支的權重,從而實現(xiàn)對復雜場景的全面理解。
多模態(tài)融合
HumanOmni能夠同時處理視覺(視頻)、聽覺(音頻)和文本信息。通過指令驅動的動態(tài)權重調整機制,模型能夠將不同模態(tài)的特征進行融合,實現(xiàn)對復雜場景的全面理解。這種多模態(tài)融合能力使得HumanOmni在情感識別、面部描述和語音識別等方面表現(xiàn)出色。
技術原理
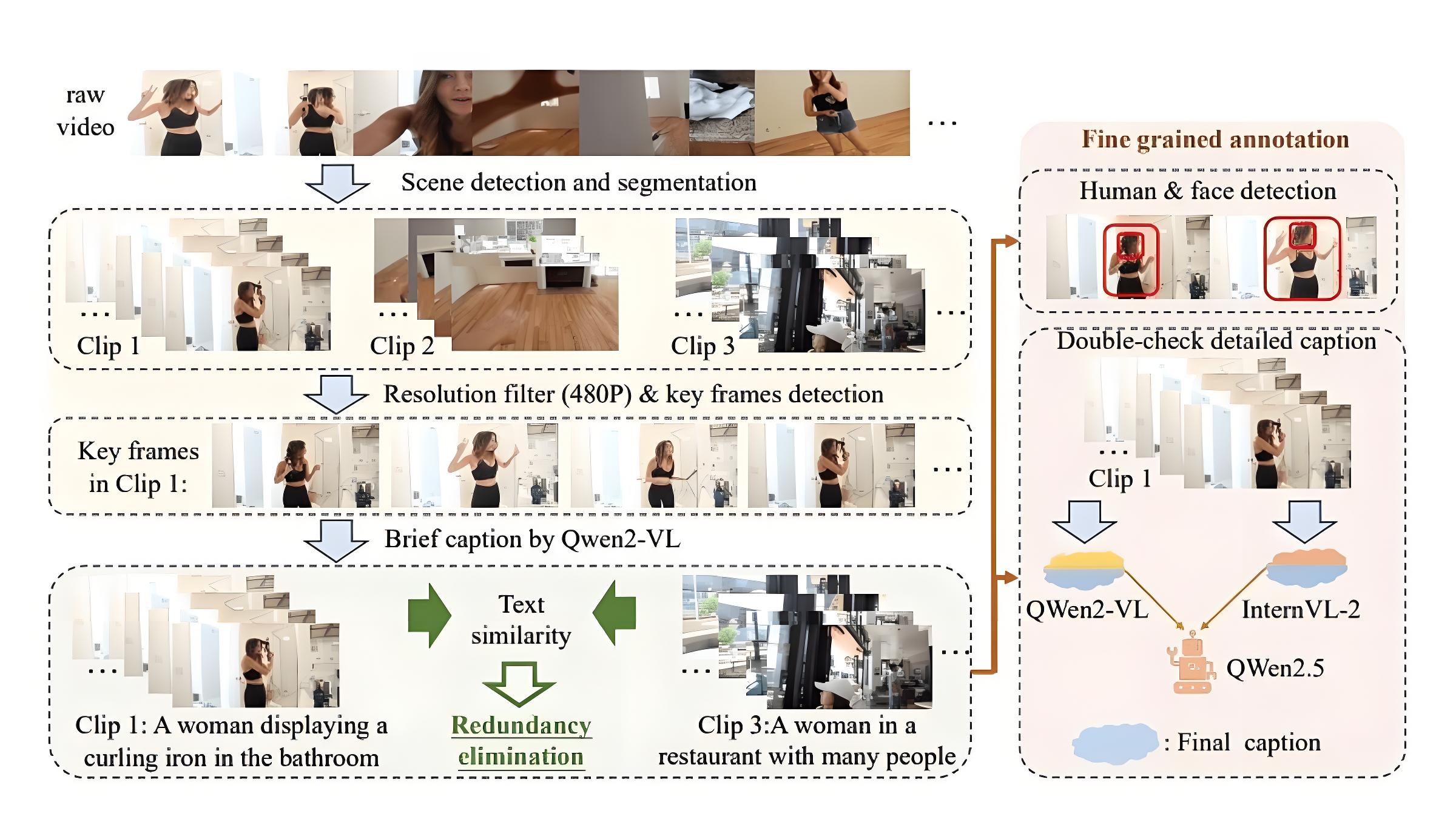
HumanOmni的技術原理包括以下幾個方面:
-
多模態(tài)融合架構:通過視覺、聽覺和文本三種模態(tài)的融合,實現(xiàn)對復雜場景的全面理解。
-
動態(tài)權重調整機制:通過BERT對用戶指令進行編碼,生成權重,動態(tài)調整不同分支的特征權重。
-
聽覺與視覺的協(xié)同處理:使用Whisper-large-v3的音頻預處理器和編碼器處理音頻數(shù)據(jù),通過MLP2xGeLU將其映射到文本域。
-
多階段訓練策略:分為三個階段,逐步構建視覺能力、發(fā)展聽覺能力,并進行跨模態(tài)交互集成。
應用場景
HumanOmni的應用場景非常廣泛,主要包括以下幾個領域:
-
影視與娛樂:可用于虛擬角色動畫生成、虛擬主播和音樂視頻創(chuàng)作。
-
教育與培訓:可以創(chuàng)建虛擬教師或模擬訓練視頻,輔助語言學習和職業(yè)技能培訓。
-
廣告與營銷:能生成個性化廣告和品牌推廣視頻,通過分析人物情緒和動作,提供更具吸引力的內(nèi)容。
-
社交媒體與內(nèi)容創(chuàng)作:可以幫助創(chuàng)作者快速生成高質量的短視頻,支持互動視頻創(chuàng)作,增加內(nèi)容的趣味性和吸引力。
項目資源
HumanOmni的項目資源包括:
-
HuggingFace模型庫:https://huggingface.co/StarJiaxing/HumanOmni-7B
-
arXiv技術論文:https://arxiv.org/pdf/2501.15111
總結
HumanOmni作為一款專注于人類中心場景的多模態(tài)大模型,憑借其強大的技術優(yōu)勢和廣泛的應用場景,正在為影視、教育、營銷和內(nèi)容創(chuàng)作等領域帶來全新的可能性。無論是開發(fā)者還是內(nèi)容創(chuàng)作者,都可以通過HumanOmni實現(xiàn)更多創(chuàng)新。未來,隨著技術的不斷進步,HumanOmni有望在更多領域發(fā)揮其獨特價值。



















