Video-LLaVA2 – ChatLaw推出的開源多模態(tài)智能理解系統(tǒng)
Video-LLaVA2是什么
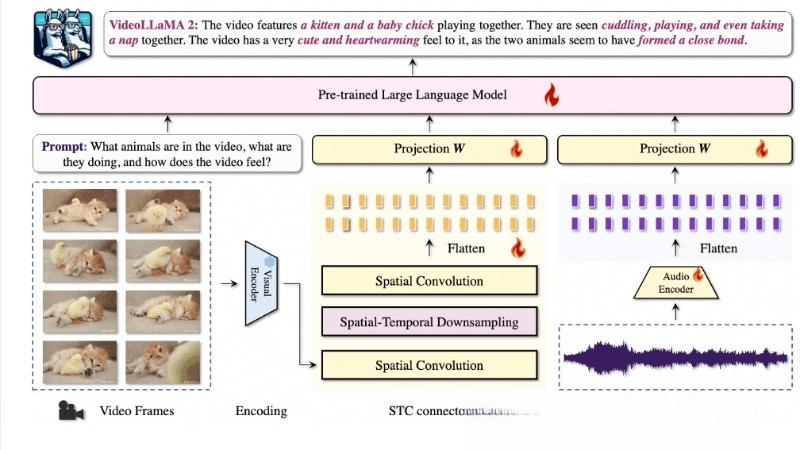
Video-LLaVA2是由北京大學(xué)ChatLaw課題組推出的開源多模態(tài)智能理解系統(tǒng),通過創(chuàng)新的時(shí)空卷積(STC)連接器和音頻分支,提升了視頻和音頻理解能力。模型在視頻問答和字幕生成等多個(gè)基準(zhǔn)測(cè)試中表現(xiàn)出色,與一些專有模型相媲美,同時(shí)在音頻和音視頻問答任務(wù)中也展示了優(yōu)越的多模態(tài)理解能力。
Video-LLaVA2的主要功能
- 視頻理解:能準(zhǔn)確識(shí)別視頻中的視覺模式,并理解隨時(shí)間變化的情景。
- 音頻理解:集成了音頻分支,可以處理和分析視頻中的音頻信號(hào),提供更豐富的上下文信息。
- 多模態(tài)交互:結(jié)合視覺和聽覺信息,提供更全面的理解和分析視頻內(nèi)容的能力。
- 視頻問答:在多項(xiàng)視頻問答任務(wù)中表現(xiàn)出色,能準(zhǔn)確回答關(guān)于視頻內(nèi)容的問題。
- 視頻字幕生成:能為視頻生成描述性字幕,捕捉視頻的關(guān)鍵信息和細(xì)節(jié)。
- 時(shí)空建模:通過STC連接器,模型能更好地捕捉視頻中的時(shí)空動(dòng)態(tài)和局部細(xì)節(jié)。
Video-LLaVA2的技術(shù)原理
- 雙分支框架:模型采用視覺-語言分支和音頻-語言分支的雙分支框架,各自獨(dú)立處理視頻和音頻數(shù)據(jù),然后通過語言模型進(jìn)行跨模態(tài)交互。
- 時(shí)空卷積連接器(STC Connector):一個(gè)定制的模塊,用于捕捉視頻數(shù)據(jù)中的復(fù)雜時(shí)空動(dòng)態(tài)。與傳統(tǒng)的Q-former相比,STC連接器更有效地保留空間和時(shí)間的局部細(xì)節(jié),同時(shí)不會(huì)產(chǎn)生大量的視頻標(biāo)記。
- 視覺編碼器:選擇圖像級(jí)的CLIP(ViT-L/14)作為視覺后端,與任意幀采樣策略兼容,提供靈活的幀到視頻特征聚合方案。
- 音頻編碼器:BEATs等先進(jìn)的音頻編碼器,將音頻信號(hào)轉(zhuǎn)換為fbank頻譜圖,并捕捉詳細(xì)的音頻特征和時(shí)間動(dòng)態(tài)。
Video-LLaVA2的項(xiàng)目地址
- GitHub倉庫:https://github.com/DAMO-NLP-SG/VideoLLaMA2?tab=readme-ov-file
- arXiv技術(shù)論文:https://arxiv.org/pdf/2406.07476
- 在線體驗(yàn)鏈接:https://huggingface.co/spaces/lixin4ever/VideoLLaMA2
如何使用Video-LLaVA2
- 環(huán)境準(zhǔn)備:確保計(jì)算環(huán)境中安裝了必要的軟件和庫,包括Python、PyTorch、CUDA(如果使用GPU加速)以及Video-LLaVA2模型的依賴包。
- 獲取模型:從Video-LLaVA2的官方GitHub倉庫下載或克隆模型的代碼庫。
- 數(shù)據(jù)準(zhǔn)備:根據(jù)應(yīng)用場(chǎng)景,準(zhǔn)備視頻和/或音頻數(shù)據(jù)。數(shù)據(jù)應(yīng)該是模型能處理的格式,例如視頻文件可能需要轉(zhuǎn)換為幀序列。
- 模型加載:使用Video-LLaVA2提供的代碼加載預(yù)訓(xùn)練的模型權(quán)重。涉及到加載視覺和音頻編碼器,以及語言模型。
- 數(shù)據(jù)處理:將視頻幀和音頻信號(hào)輸入模型進(jìn)行處理。視頻幀需要預(yù)處理,如調(diào)整大小、歸一化等,匹配模型的輸入要求。
- 模型推理:使用模型對(duì)輸入數(shù)據(jù)進(jìn)行推理。對(duì)于視頻理解任務(wù),包括視頻問答、視頻字幕生成等。
Video-LLaVA2的應(yīng)用場(chǎng)景
- 視頻內(nèi)容分析:自動(dòng)分析視頻內(nèi)容,提取關(guān)鍵信息,用于內(nèi)容摘要、主題識(shí)別等。
- 視頻字幕生成:為視頻自動(dòng)生成字幕或描述,提高視頻的可訪問性。
- 視頻問答系統(tǒng):構(gòu)建能回答有關(guān)視頻內(nèi)容問題的智能系統(tǒng),適用于教育、娛樂等領(lǐng)域。
- 視頻搜索和檢索:通過理解視頻內(nèi)容,提供更準(zhǔn)確的視頻搜索和檢索服務(wù)。
- 視頻監(jiān)控分析:在安全監(jiān)控領(lǐng)域,自動(dòng)檢測(cè)視頻中的重要事件或異常行為。
- 自動(dòng)駕駛:輔助理解道路情況,提高自動(dòng)駕駛系統(tǒng)的感知和決策能力。
? 版權(quán)聲明
本站文章版權(quán)歸奇想AI導(dǎo)航網(wǎng)所有,未經(jīng)允許禁止任何形式的轉(zhuǎn)載。
相關(guān)文章




















奇想AI導(dǎo)航網(wǎng)收錄了國內(nèi)外數(shù)百個(gè)不同類型的AI工具,每日更新和添加最新AI工具,奇想AI導(dǎo)航網(wǎng)還推薦了AI學(xué)習(xí)開發(fā)的常用網(wǎng)站、框架和模型,幫助你加入人工智能浪潮,自動(dòng)化高效完成任務(wù)!
Ctrl + D 或 ? + D 收藏本站到瀏覽器書簽欄。