一、通古大模型是什么?
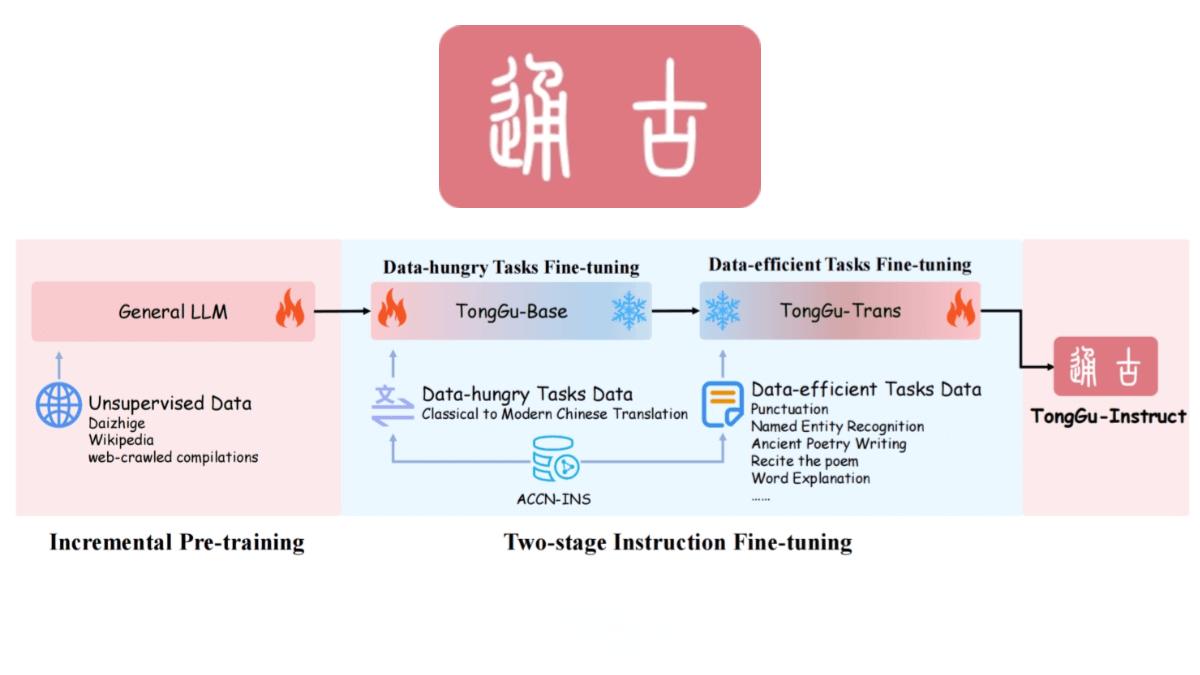
通古大模型是華南理工大學深度學習與視覺計算實驗室(SCUT-DLVCLab)推出的專注于古籍文言文處理的AI語言模型。它基于百川2-7B-Base進行增量預訓練,利用24.1億古籍語料進行無監督訓練,并結合400萬古籍對話數據進行指令微調。通過冗余度感知微調(RAT)技術和檢索增強生成(RAG)技術,通古大模型在古籍處理任務中表現出色,幫助用戶更便捷地理解和翻譯古籍文獻。
二、通古大模型的主要功能
-
古文句讀 通古大模型能夠自動為古文添加標點符號,解決古籍中常見的斷句問題,幫助用戶更好地理解古文內容。
-
文白翻譯 模型支持文言文與白話文之間的雙向翻譯,將晦澀的古文翻譯為現代文,同時也可將現代文轉換為文言文,方便用戶進行古籍閱讀和研究。
-
詩詞創作 通古大模型可以生成符合古詩詞格律和風格的詩歌,用戶可以根據需求提供主題或關鍵詞,模型生成相應的詩詞作品。
-
古籍賞析 模型能對古籍中的經典篇章進行賞析,解讀其文學價值、歷史背景和文化內涵,輔助用戶深入學習古籍。
-
古籍檢索與問答 結合檢索增強技術,通古大模型可以快速檢索古籍內容,根據用戶的問題提供準確的答案,幫助用戶高效獲取古籍信息。
-
輔助古籍整理 模型能識別古籍中的文字錯誤、缺漏等問題,提供修復建議,輔助古籍整理和數字化工作。
三、通古大模型的技術原理
-
基礎模型架構 通古大模型基于百川2-7B-Base進行增量預訓練,該模型為通古大模型提供了基礎的語言理解和生成能力。
-
無監督增量預訓練 模型在24.1億古籍語料上進行無監督增量預訓練,使模型學習古籍的語言風格和結構,為后續的古籍處理任務奠定基礎。
-
多階段指令微調 通古大模型采用了多階段指令微調技術,提出了冗余度感知微調(RAT)方法。在提升下游任務性能的同時,保留了基座模型的能力。
-
檢索增強生成(RAG)技術 通古大模型結合了檢索增強生成(RAG)技術,減少知識密集型任務中的幻覺問題,提高生成內容的準確性和可靠性。
四、通古大模型的項目地址
-
HuggingFace模型庫:https://huggingface.co/SCUT-DLVCLab/TongGu-7B-Instruct
五、通古大模型的應用場景
-
古籍處理與數字化 通古大模型能高效處理古籍文獻,支持文白翻譯、句讀標點和古籍檢索等功能,輔助古籍整理工作,提升古籍數字化的效率。
-
教育支持 教師可以利用通古大模型生成教案、教學PPT,設計課堂互動環節。學生則可以通過模型獲得文言文翻譯、成語解釋和詩詞創作等功能,幫助他們更好地理解古文。
-
文化傳承與普及 通古大模型通過降低古籍閱讀難度,讓更多人接觸和理解中華傳統文化,促進文化傳承與普及。
-
學術研究 通古大模型為古籍研究提供了強大的技術支持,幫助學者快速檢索和分析古籍內容,提升研究效率。
六、通古大模型的意義與未來展望
通古大模型的推出,不僅是古籍處理領域的一次重要突破,也為中華傳統文化的傳承與普及提供了強有力的技術支持。未來,隨著技術的不斷進步,通古大模型有望在更多領域發揮其獨特優勢,助力古籍數字化和文化傳承邁向新的高度。
結語
通古大模型作為華南理工大學推出的專注于古籍文言文處理的AI語言模型,憑借其強大的功能和技術優勢,正在為古籍數字化和文化傳承開辟新的道路。無論是教育工作者、研究人員,還是普通用戶,都能從中受益,感受古籍的魅力與智慧。



















